Model Validation and Data Assimilation
The key objective of the Validation and Assimilation subgroup is to optimize and standardize pre- and post-processing efforts across the HiMAT on the themes of evaluation methodology and assimilation techniques. In particular, we ask questions such as:
- What ground measurements are available for model evaluation?
- What remote sensing and modeling datasets can we use to help evaluate our models?
- What are the best practices for validation methods and tools?
- What observations and methodologies should we use within our data assimilation framework?
Ground Measurements
Ground measurements of energy, water and carbon balance variables are essential to validate modeling and remote sensing efforts of HiMAT investigations. However, ground measurements are extremely rare in the region, and the issue of representativeness error between the ground-based observations and model estimates is ever present. Our subgroup aims at collating and keeping an inventory of available ground observations from various public and private sources, their quality and shareability conditions. The database includes meteorological measurements, as well as snow depth, soil moisture, groundwater, streamflow, carbon fluxes, etc.
Remote Sensing and Modeling Datasets
Beside ground measurements, the HiMAT teams may compare their results with existing remote sensing and modeling products (e.g., resulting from HiMAT-1). These are particularly relevant for remote regions like HMA, where ground-observations are sparse in space and time. We are interested in standardizing existing remote sensing and modeling products to ease their use within the rest of the HiMAT team. Examples of such products include vegetation (e.g., LAI from MODIS), snow water equivalent products (e.g., snow reanalysis from HiMAT-1), snow cover products (e.g., MODSCAG), etc.
Validation Methods and Tools
A major goal of our subgroup is to standardize cohesive methodologies and tools that can be used for interdisciplinary evaluation across team members. The lack of an extensive network of ground observations encourages us to seek innovative and indirect ways to evaluate our products. We aim at investigating indirect evaluation methods such as: “distributional validation”, a method to validate any summary statistics of interest (Warr et al. submitted) or “latent variable modeling”, a statistical approach that relates observed variables to unobserved ones (Kumar et al., 2017). A practical indirect evaluation example is given by Loomis et al., (2019), where several datasets are compared via the mean of computing regional trends from GRACE Level 1 data (Figure 1).
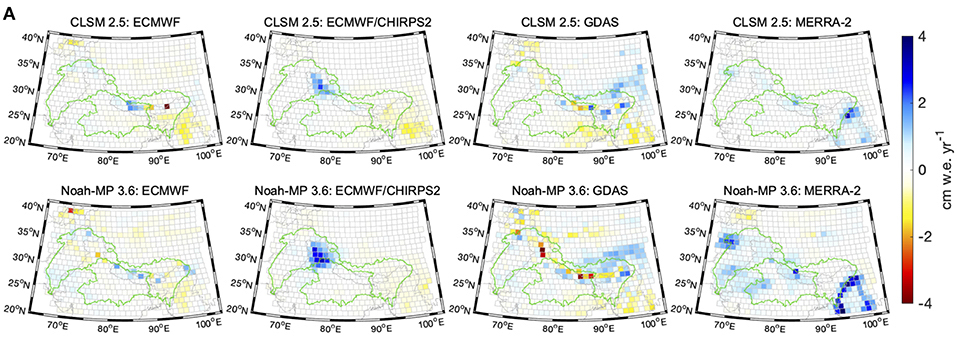
Several teams within HiMAT include efforts in data assimilation. However, the modeling and assimilation systems of the individual teams are different in their nature (e.g., assimilation of retrievals vs. level-1 observations), region of interest (e.g., global vs. regional), etc. Yet, we can learn from these differences by continuously checking products, algorithms, and models across teams.
Our sub-group is composed upon the following members:
| PI Team | Subgroup Members |
|---|---|
| B. Zaitchik | Sujay Kumar |
| S. Rupper | Matt Heaton |
| K. Rittger | Karl Rittger, Ned Bair, Adina Racoviteanu |
| E. Nikolopoulos | Viviana Maggioni, Manos Anagnostou, Giulia Sofia |
| S. Kumar | Bart Forman, Sujay Kumar, Jawairia Ahmad, Viviana Maggioni, Yuan Xue |
| C. Gleason | Kosta Andreadis |
| M. Girotto | Lauren Andrews, Manuela Girotto, Rolf Reichle, Jongming Park, Elias Massoud |
References:
- Kumar, S. V., Wang, S., Mocko, D. M., Peters‐Lidard, C. D., & Xia, Y. (2017). Similarity assessment of land surface model outputs in the North American Land Data Assimilation System. Water Resources Research, 53(11), 8941-8965.
- Loomis, B. D., Richey, A. S., Arendt, A. A., Appana, R., Deweese, Y. J., Forman, B. A., … & Shean, D. E. (2019). Water storage trends in high mountain Asia. Frontiers in earth science, 7, 235.
- Warr L., Heaton M.J., Christensen W.F., White P. and Rupper S. “Distributional Validation of Precipitation Data Products with Spatially Varying Mixture Models” submitted to Environmetrics.